Transformers are giant robots coming from Cybertron. There are two Transformer tribes: the Autobots and the Decepticons. They have been fighting each other over the Allspark, a mythical artifact capable of building worlds and mechanical beings. Well, there is also another kind of Transformers, but those are not about warfare. However they are pretty good at language understanding. Let’s see how!
Attention is all you need! #
To understand what the transformer does, one first needs to understand the principle of Attention in neural networks. Attention is a mechanism generating a weights vector $A = \alpha_1,\dotsc, \alpha_n , \ \alpha \in \mathbb{R}$ allowing the neural network to focus on specific parts of an input of length $n$. Since the relationship between two words is not commutative (how important a word $w_1$ is w.r.t a word $w_2$ is different from how $w_2$ is important w.r.t $w_1$), there needs to be two sets of weights associated with a word $w$:
- How $w$ is important w.r.t every other word
- How every other word is important w.r.t $w$
- … and there needs to be a third set of weights which is used to compute the final vector $A$, after having considered 1. and 2.
Each word $w$ is therefore transformed to an embedding $x$ of dimension $d$ and then multiplied with three weight matrices. The results of these operations are respectively named $Q$, $K$ and $V$. To get the attention weights, we use the following formulas:
$$\text{Attention}(Q, K, V) = \sigma\left(\frac{QK^\mathrm{T}}{\sqrt{d}}\right)V$$
$$\sigma(t_i) = \frac{e^{t_i}}{\sum_{j=1}^{N}{e^{t_j}}}$$
We perform dot products between $Q$ and $K$: $QK^\mathrm{T} = q_1k_1 + q_2k_2+ \dotsc + q_{nd}k_{nd}$ and divide by $\sqrt{d}$, which is proportional to the size of the embedding vectors, to scale down the results so that it doesn’t grow to a large number. We then apply the softmax function $\sigma$ so that the values sum up to 1, and multiply by $V$. This allows the network to understand the relative importance of each word, and is parallelizable.
Attention in Transformers #
Transformers work by stacking blocks onto each other. Each block is composed of an attention unit, a layer normalization, a dense layer and a second layer normalization. Residual connections are added after the attention unit and after the dense layer.

Diagram of an attention block.
Layer normalization #
The goal of layer normalization is to speed up the convergence of the network by making sure the means of the embeddings are 0. This makes the learning faster, because else the value of their gradients will not be centered and the weight’s update will thus not have an optimal modularity. As the name says, in layer normalization, normalization is done layer-wise, meaning that the mean and variance of the layer is computed for every training example.1
$$LayerNorm(x) = \gamma\Big(\frac{x - \mu_x}{\sqrt{var(x) + \epsilon}}\Big) + \beta$$
$\gamma$ and $\beta$ are learnable parameters that can make the network to learn a distribution potentially more optimal than the normal distribution. They are initially set to 1 and 0, respectively.
Dense layer #
Dense layers (also known as feedforward neural network) are simple neural networks where every input is connected to $H$ perceptrons.
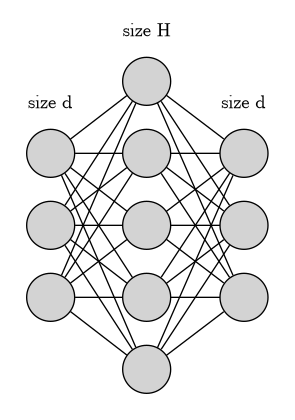
Diagram of a dense layer in an attention block. The input is of same size as $d$ and $H$ is the size of the dense layer.
In case of transformers, the value of the $j$th perceptron is:
$$\sum_{i=1}^d ReLu(w_{ij} \cdot \alpha_i + b_j)$$
$$ReLu(x) = \max(0, x)$$
Where $w$ and $b$ are the weight and bias terms of the perceptrons.
Positional encoding #
As the transformer blocks are not stateful, they are not aware of the order in which the words come, yet this is obviously important for language understanding, we need a way to encode the position of the words inside the model, prior to feeding them to the transformer blocks, For this, we can encode the position of each word in the input of size $n$, and add the encoding values to the embeddings. The encoding may be done with a custom function mapping each word position $1,\dotsc, n$ to continuous values, or with embeddings of the same dimension as the word embeddings, to facilitate the broadcast operation during the sum.
Conclusion #
Transformers have revolutionized Natural Language Processing by reducing the time required to train the models compared to Recurrent Neural Networks. Because they are not sequential, attention-based models can process words in parallel, which is a major speed improvement. This allows the model to scale better, both in term of parameters and dataset size. This is also useful for interpretability, because attention weights allow one to easily understand the part of the input which contributed to the most to the predictions.
-
As opposed to batch normalization where the mean and variance are computed for the whole batch. ↩︎